Introduction to Statistics
Introduction to Statistics
Statistics is the science of collecting, analyzing, interpreting, presenting, and organizing data.
Descriptive Statistics: Summarize and interpret data to provide meaningful insights.
Inferential Statistics: Make predictions about a population based on sample data.

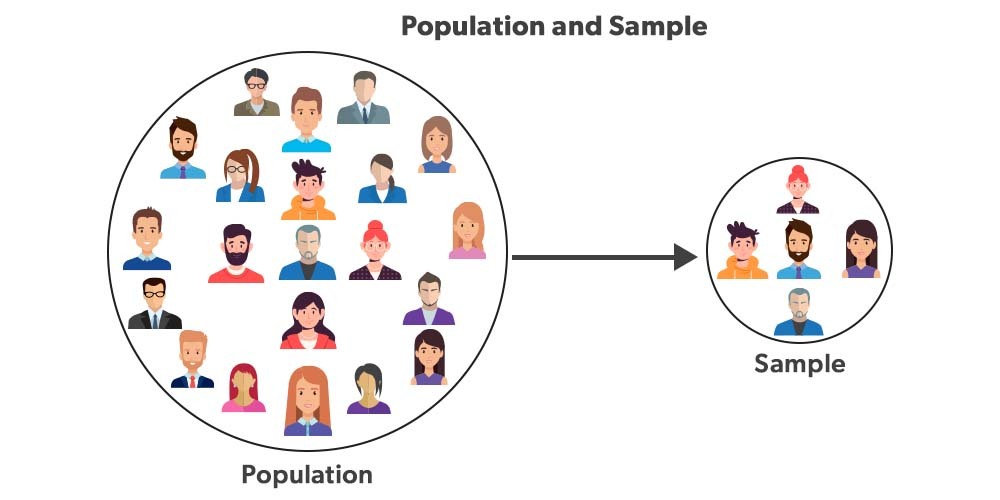
Population vs. Sample
Population: The entire group that is the subject of the study.
- Example: All 7,000 students at AUC
- Notation: \(N\) for size, \(\mu\) for mean, \(\sigma\) for standard deviation
Sample: A subset of the population used for making inferences about the population.
- Example: A survey of 100 AUC students
- Notation: \(n\) for size, \(\bar{x}\) for mean, \(s\) for standard deviation
Measures of Central Tendency 3/3
When to use each measure
- Use the mean for normally distributed data
- Use the median when the data is skewed or has outliers
- Use the mode when dealing with categorical data

Measures of Dispersion 2/2
When to use each measure
- The range is great for a quick overview, but it is sensitive to outliers.
- Variance and standard deviation are more robust and provide a clearer picture of the spread in your data.
Setting-up R & RStudio & Google Colab
